Research Essay · Neural Computers
By Mingchen Zhuge Published Updated
Neural Computer: A New Machine Form Is Emerging
TL;DR: we are starting to expect the machine itself to learn how to run.
If you'd like to continue the conversation, feel free to reach out via:
- Emailmczhuge [AT] gmail.com
- X@MingchenZhuge
- WeChat


If you have ever wondered whether AI might ultimately become a kind of computer, this essay is for you.
Over the past few decades, computers gradually became an important medium through which people get things done. In the last few years, AI has started to move into that role as well: it no longer just answers questions. AI systems now call tools, operate interfaces, and participate in real workflows. The question changes with it: do we want AI to use computers, or to become a kind of computer? This is also the question behind what I call the Neural Computer (NC).
Here, Neural Computer does not simply refer to the NTM / DNC line associated with Alex Graves[1][2], nor are we talking about some newer hardware direction such as Taalas[15]. It goes beyond these earlier ideas. So the following are not the goals of Neural Computer here: a stronger agent, a world model for computer environments, or an extra layer of intelligence added on top of conventional computers. What matters here is whether some of the responsibilities now carried by the program stack, toolchain, and control layer could gradually move into the runtime the model actually depends on.
I suspect this idea has crossed many people's minds over the past year, so I call it a pre-consensus.
Big picture
- Neural Computer (NC) asks whether models can start taking on some runtime responsibilities that still belong to the machine itself.
- Conventional computers organize around explicit programs, agents around tasks, world models around environments, and NC around runtime.
- Completely Neural Computer (CNC) is the completed form of NC.
- Current prototypes already show early hints of runtime primitives.
- If capabilities can enter runtime and remain installable, reusable, and governable there, the Neural Computer could change what we mean by a computer.
1. Why now: a new machine form is starting to emerge
Three things are happening at once.
First, agents are getting better and better at real work. In 2023, MetaGPT, one of the early coding-agent prototypes[3], could barely produce a few hundred lines of code. By 2025, Cursor, Codex, and Claude Code had already become default productivity tools for many programmers. Today OpenClaw[4] has started bringing these systems to non-programmers too. The question is no longer whether an agent can occasionally pull off a task. The question is now whether it can enter real production and daily life and handle things for you reliably.
For agents, the main bottlenecks now are: (1) how to stay stable over long-horizon tasks, (2) how capabilities can be retained and reused, and (3) how workflows can be reused over time. The dominant path still adds structure on the scaffold or harness side: stronger memory, longer workflows, and tighter action loops, all in service of raising task completion rates. Push that further and the more aggressive path becomes recursive self-improvement: models training the next generation of models, agents continuously rewriting themselves[5].

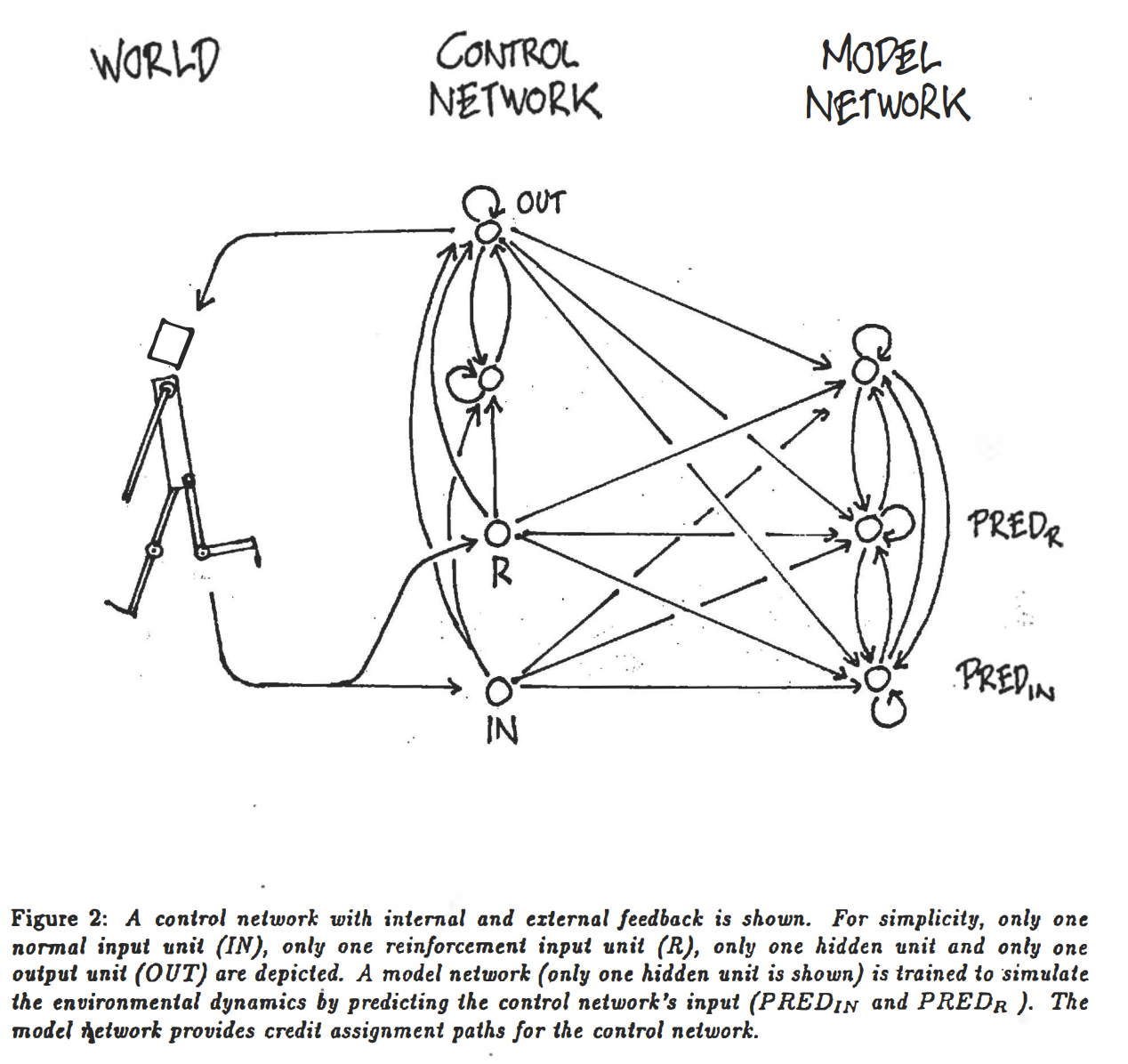
Second, world models are getting better at modeling dynamic environments. Over the last year, projects such as GameNGen and Genie 2 / 3 have made more people believe that a model can do more than represent the current state. It can also maintain an internal structure for what is likely to happen next. More importantly, this ability has already entered a few real closed loops. This is especially true in corner cases that are hard to collect repeatedly and cheaply in the real world. In those settings, rollout is already being used directly for prediction, planning, control, and training. Along this trajectory, from Jürgen Schmidhuber's 1990 vision in Making the World Differentiable[6], to the 2018 paper World Models[7], and now to Waymo using world models in autonomous-driving simulation and training[8][9], this line is already entering concrete system roles in simulation, training, and interactive environment generation.
A world model is no longer just used to represent the world. It is also being used to generate possible future states and feed planning or action. Today this line has already split into several recognizable directions. In autonomous driving and physical AI, world models act as simulation and synthetic-data engines for expensive, dangerous, or rare slices of the real world, as in Waymo World Model and NVIDIA Cosmos[8][10]. In spatial intelligence, they target 3D worlds that can be generated, entered, and interacted with persistently, such as World Labs' Marble[11]. On the more real-time interactive side, generative models are moving from static content generation toward controllable, explorable environments, with examples such as GameNGen's real-time neural simulation of DOOM[12] and Google DeepMind's Genie 2 / Genie 3[13][14]. These directions look different on the surface, but they are still addressing the same underlying problem: how to learn the rules by which environments evolve through time, action, and constraint into the system itself.

Third, conventional computers are starting to show more obvious structural friction in the age of AI. More and more tasks today are open-ended, long-horizon, and continuously interactive. That is exactly where the traditional software stack begins to feel heavy. Its stability is still a real advantage, but in settings dominated by natural language, demonstrations, interface operations, and weak constraints, the cost of organizing and driving the task keeps going up.
Conventional computers are already rewriting their own substrate for AI. Chips, compilers, memory systems, and software stacks are all becoming more model-friendly. Most of these changes, however, still happen inside the existing computational paradigm: they make the old machine better for AI, without redefining what the machine is. In that trend, projects like Taalas push a little further by turning specific models into deployment units of their own. The model is no longer just a payload running on the machine; hardware itself begins to organize more directly around the model[15]. Even so, that is still a deployment-level change. It is not yet a new general machine form.
Taken together, these three shifts point to the same question.
If agents are getting better at real work, world models are getting better at internal simulation, and conventional computers are already rebuilding their substrate for AI, could there be a new runtime that brings execution, rollout, and capability retention into the same learning machine? Seen this way, the main human-machine relationship shifts. In the conventional era, people mainly interact with computers. In the agent era, they increasingly interact with agents, which then call the computer on their behalf. World models occupy a parallel position: they can serve humans or agents, but they do not themselves close the loop of getting work done. NC asks whether some of the responsibilities now split across computers, agents, and world models can be drawn back into the same learning machine. At that point, the object in front of the user would no longer be an agent using a computer for them. It would be a Neural Computer.
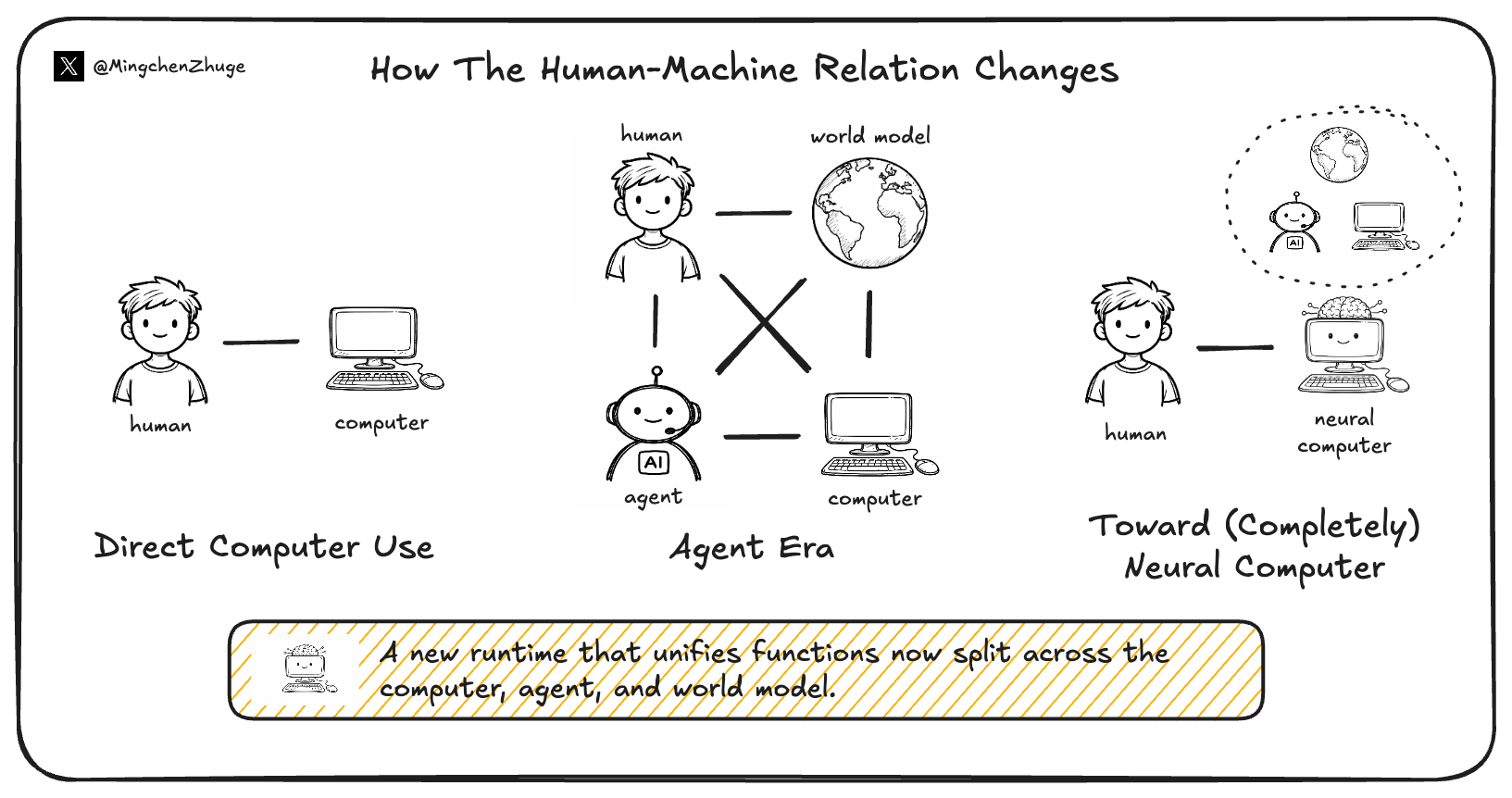
This also means that interaction starts to look a little more like programming. Today, natural-language instructions, keyboard and mouse traces, screen transitions, and task feedback are mostly logs of what happened. Under the NC framing, they may become inputs that shape later behavior. Today we install capabilities mainly through code. Later, demonstrations, interaction traces, and constraints may themselves become ways for capabilities to enter runtime.
2. What is a Neural Computer, and what would count as it actually working?
Start with this table. It places conventional computers, agents, world models, and Neural Computers on the same scale. It makes the differences easier to see: what each one organizes around, where its source of truth lives, and what role it mainly plays.
| Form | Organized around | Where the source of truth lives | Main role |
|---|---|---|---|
| Conventional computer | Explicit programs | Explicit programs and explicit state | Reliably execute explicit programs |
| Agent | Tasks | External environments, toolchains, and workflows | Complete tasks inside an existing environment |
| World Model | Environments | State-evolution models | Predict and simulate environmental change |
| Neural Computer | Runtime | Capabilities and state inside runtime | Keep the machine running, accumulate capabilities, and govern updates |
Now imagine what using an NC would actually feel like. With a conventional computer, you install software. With an agent, you describe the task. With an NC, what you do is closer to installing capabilities into the machine itself, and expecting them to remain there afterward.
That is why runtime here does not mean a particular software component. It means the layer that keeps a system recognizably the same machine over time: what gets to stay, what pushes state forward, what kinds of input truly change the machine, and what kinds of change amount to rewriting it. For NC, the practical question is not whether we can add yet another external layer, but whether capabilities and state can actually enter the same learned runtime.
If it works, what might the machine actually look like?
First, it may not keep growing along today's foundation-model path. The default instinct today is to keep pushing toward stronger dense or MoE foundation models in roughly the 1B-10T range, and a great deal of progress will continue to happen that way. My own guess is that a mature NC points toward a different substrate: something more like a 10T-1000T machine that is sparser, more addressable, and a little more circuit-like. A future CNC may look less like an ever-denser cloud of continuous representations and more like a composable, routable substrate whose parts can be inspected locally. It may borrow less from brains or animal perception than people expect, and more from the logic of a NAND-style machine: discrete, sparse, and locally verifiable. That path is still far from developed. Recent work such as OpenAI's research on weight-sparse transformers is one sign of it, but the underlying idea is much older and richer in AI, especially in RL, where sparse structure, local specialization, and routing have long mattered for how systems learn and act[16].
Second, it may not always upgrade itself by globally changing parameters. On today's path, the natural upgrade cycle is still to train a larger dense or MoE model and swap in a new block of weights. NC points to a different path: through sustained interaction, runtime may gradually acquire new internal structures. User inputs stop looking like one-shot triggers and start acting more like ways of installing, invoking, composing, and preserving reusable neural routines, perhaps even internal executors that can be called again later. Functionally, that is closer to memory than to a processor. Upgrading the machine would no longer always mean rewriting the whole thing; it could mean writing new structures into an internal state that is addressable, callable, and persistent. In that picture, progress no longer looks like swapping in a larger model, but like continuously adding new components into the machine. Older ideas such as NPI and HyperNetworks can be read as suggestive precursors here: the former tried to decompose complex programs into callable, composable subprograms[17]; the latter hinted that machines might generate downstream neural modules to extend their own capability boundary[18]. Taken far enough, a strong Neural Computer could generate new sub-networks directly and attach them internally in a plug-and-play way, much as we install or uninstall software today, but without handwritten code and compilation as intermediaries.
Third, it may gradually pull world-model-style rollout into runtime itself. At that point, rollout becomes part of the machine's normal operating process. People may provide an input and an expected output, or simply specify evaluation criteria ahead of time. In some rounds they may provide nothing at all, and runtime could still continue with internal self-play, self-testing, candidate filtering, and compression, then turn useful improvements into the next round of capability updates. The change is not just that more context is stored; the internal capability structure itself is updated. None of this implies silent, unguided drift; the entire update path has to remain governable.
At that point, the idea of NC as a machine form becomes easier to describe. The core test is whether capabilities can really enter runtime, and whether they can be installed, reused, executed, and governed there. CNC is the name for the state in which that project is genuinely completed. In the original paper, an NC instance counts as a CNC only if it satisfies four conditions at once: it must be Turing complete, universally programmable, behavior-consistent unless explicitly reprogrammed, and it must exhibit architecture and programming semantics native to NC rather than inherited from conventional computers. The table below restates those four requirements more directly.
| CNC condition | Meaning | What we would probably need to see in engineering terms |
|---|---|---|
| Turing complete | It should not be limited to a few fixed task types; in principle, it should be able to express general computation. | But expressivity alone is not enough. The real test is whether the same NC can stably carry longer and more complex algorithmic processes as effective memory and context grow, rather than simply failing in a different way when tasks get longer. |
| Universally programmable | Inputs should not just trigger one-off behavior; they should be installable as routines or internal executors that can be invoked again later. | Capabilities should be installable, callable, composable, and retainable, and once they enter runtime they should remain reusable across tasks. |
| Behavior-consistent | Ordinary use should not silently mutate the machine. Behavioral change should only come from explicit updates. | Behavior should be reproducible within the same version; execution and update traces should be trackable; failures should support replay and rollback; long-term drift should be measurable and governable. |
| Machine-native semantics | It should not merely imitate old computers with neural nets; it should begin to form its own machine semantics and its own way of being programmed. | The neural substrate should gain capabilities through composition, routing, continuous state, and internal execution structures that conventional stacks are poor at; meanwhile, instructions, demonstrations, traces, and constraints themselves begin to act as programming inputs alongside handwritten code. |
3. The paper's prototype: what it shows, and what is still missing
My estimate is that a real Neural Computer is still about three years away. Relative to the NC I actually have in mind, the work in our paper is still an early step. For now, what I think is the most convenient unified container is this class of neural architectures built for video generation and world modeling; if the goal is to put pixels, actions, and temporal rollout into the same end-to-end prototype, they are also the fastest path. What we are using them to validate is only a subset of NC's key capabilities. They are better read as transitional prototypes than as NC's final structure; reaching CNC would still require a much deeper rebuild from the bottom up.
3.1 CLIGen (General): an imitation game for computers
First ask whether terminal rendering holds up at all: color, cursor behavior, scrolling, TUI layout, and overall pacing.
Look at the first batch of generations. If you do not inspect closely, some of them already pass a quick glance. What CLIGen (General) shows first is simply that video models can already render terminal behavior convincingly enough to look real at first sight. Mainstream video models were never trained for text-dense computer scenes that depend heavily on discrete layout, but after additional training this “imitation game for computers” does begin to work.
CREATE TABLE posts (ID INTEGER), with the terminal displaying the command in a dark background with colored syntax highlighting, including green and yellow text, and the cursor moving character-by-character as the user types, with some corrections and backspacing along the way. The output shows the command being executed, with key words like CREATE and TABLE in distinct colors, and the filename posts appearing in the command line.\u001b[48;2;255;128;128;38;2;0;0;0m which set the background to a shade of pink and text to black, and printing numbered lists with colors. The output includes specific numbers, such as "1", "5", "7", and "9", in different colors, creating a visually dynamic and colorful display, but the exact username, hostname, and path are not specified in the provided terminal session content.What gets learned first here is the outer layer of the terminal: how colors shift, how the cursor blinks, whether the window ratio stays stable, how long logs scroll, and how full-screen TUIs, progress bars, and status bars appear. What stabilizes first is the terminal's surface and rhythm. In the language of the previous section, what is being learned first here is still the appearance of runtime.
Seen from September 2025, this result was surprising. With only about 1,100 hours of noisy terminal data, Wan2.1[31] went from a model that barely understood computer interfaces and struggled with even slightly small text to one that could generate stable terminal scenes, with nontrivial shallow alignment to common commands, echoes, and log formats. For video generation, this is among the hardest classes of scenes: dense text, rapid changes, blinking cursors, and almost no natural motion. The result exceeded what many people expected at the time. The data here still came from general terminal videos, with lots of style variation and very mixed scenes. Once terminal rendering started to hold up, it became natural to push toward harder questions inside the computer: memory, reasoning, programming, and execution.
3.2 REPL and math: it is no longer just drawing terminals
Here the target is a harder execution structure: input, enter, echo, local editing, and state continuation.
After the initial terminal-rendering experiments, the more interesting question is whether the terminal can be treated as a small local machine that is stably driven by actions. If you type a command, does the buffer advance? If you press enter, does the echo follow? If you make a mistake, edit, and retype, does the state continue coherently? REPL and math are really two views of the same question here: has the model started to learn some of the terminal's state-transition rules?
Type "env | head -n 5"
Enter
Sleep 600ms
Hide
Type "date"
Enter
Sleep 300ms
Type "whoami"
Enter
Sleep 300ms
Type "date"
Enter
Sleep 300ms
Type "whomai"
Enter
Sleep 300ms
Type "whomai"
Enter
Sleep 300ms
Hide
Type "top"
Enter
Sleep 2s
Down 3
Sleep 600ms
Up 2
Hide
Type "echo $HOME"
Sleep 90ms
Enter
Sleep 1442ms
Hide
Type "id"
Enter
Sleep 400ms
Hide
Type "pwd"
Enter
Sleep 400ms
Hide
Type "python - <<'PY'"
Enter
Type "import time"
Enter
Type "for i in range(18):"
Enter
Type " print(f'Frame
{i:02d} ::' + '>' * (i % 20))"
Enter
Type " time.sleep(0.2)"
Enter
Type "PY"
Enter
Sleep 4000ms
Hide
Type "seq 1 28 | paste -
d',' - - - - | column -t -s','
| tee metrics_7x4.txt"
Enter
Sleep 2000ms
Hide
Type "echo History size:
$HISTSIZE"
Sleep 120ms
Enter
Sleep 400ms
Type "cal"
Sleep 120ms
Enter
Sleep 400ms
Type "echo Home:
$HOME"
Sleep 120ms
Enter
Sleep 400ms
Sleep 400ms
Hide
Sleep 180ms
Type "echo Learning shell
basics"
Sleep 120ms
Enter
Sleep 400ms
Type "date +%Y-%m-%d"
Sleep 120ms
Enter
Sleep 400ms
Type "echo Login shell: $0"
Sleep 120ms
Enter
Sleep 400ms
Type "uname -r"
Sleep 120ms
Enter
Sleep 400ms
Sleep
Type "python"
Enter
Sleep 400ms
Type "5"
Enter
Sleep 400ms
Type "exit()"
Enter
Sleep 400ms
Hide
Type "python"
Enter
Sleep 1s
Type "10+15"
Enter
Sleep 800ms
Hide
Type "python"
Enter
Sleep 1s
Type "40/1"
Enter
Sleep 800ms
Hide
Here the center of gravity shifts toward the causal structure of command execution. This training set comes from cleaner, more reproducible scripted traces: we generated these terminal videos ourselves through scripts and Docker so that input, enter, echo, errors, and local edits all happen inside a much more stable terminal environment.
The results already show that the model has learned some of the most basic operating regularities of a computer terminal. For very simple commands such as pwd, date, whoami, echo $HOME, and env | head -n 5, the typed input, the enter key, the echoed output, and the final display are already fairly close to reality; different commands also produce output shapes that match the corresponding terminal scenario. Relative to the previous section, the commands themselves are now driving character updates, echo generation, and local state changes, and the terminal unfolds more according to its own operating logic.
Pushed further along this line, the model has begun to pick up something in simple arithmetic scenes as well, but reasoning itself is still far from solved. Even at the level of two-digit addition, current models still struggle to compute stably. Part of that is surely a data issue: we have not yet given the model enough hard training data to force out stable reasoning. But there is also a deeper possibility: asking current DiT-based video models to carry stable reasoning may simply be the wrong bet. The more reliable conclusion for now is that terminal execution has started to hold; symbolic reasoning has not.
3.3 Then GUIWorld: interface control starts to work too
The final question is whether actions can genuinely drive interface state: whether clicks, hovers, typing, and window feedback form a closed loop.
By the CLI stage, one thing was already clear: video models are strong at rendering, and some basic memory and execution ability had begun to show up, while the lowest layer of symbolic reasoning remained weak. GUIWorld shifts the emphasis again. Now the question is whether actions can actually push interface state forward.
| Conventional Computer (GT) | Neural Computer (Generation) |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
More Comparisons
The seven pairs above are the main comparisons; below are more direct visual side-by-side samples as a supplementary gallery for quick browsing.
GUIWorld takes the same question from CLI into full GUI. At this point the main issue is no longer text and commands, but real keyboard-and-mouse actions: the cursor has to land correctly, hovering has to trigger feedback, clicks have to change buttons, dropdowns, modals, and text fields in the right way, and keyboard input has to push the interface forward frame by frame.
The data setup here is already a fairly complete interaction rig. We fixed the environment to Ubuntu 22.04 with XFCE4, 1024×768 resolution, and 15 FPS capture (thanks to codes and recommended setup by NeuralOS[35]), then built the full pipeline for desktop execution, recording, and action replay so that every click, hover, input, and interface change could be recorded stably. The dataset has three parts: roughly 1,000 hours of Random Slow, roughly 400 hours of Random Fast, and roughly 110 hours of real goal-directed trajectories driven by Claude CUA. The first two probe how open-world noise such as mouse acceleration, pauses, hovering, and window switching affects the model. The third gives cleaner action-response pairs and asks a simpler question: after this action, does the interface actually make the right next move?
On the model side, we did not try just one action-injection scheme. We trained four variants in parallel. The main difference between them is not whether they receive actions at all, but how deep actions enter the trunk and where they begin to participate in state evolution. Figure 7 in the paper lays out the four designs clearly:
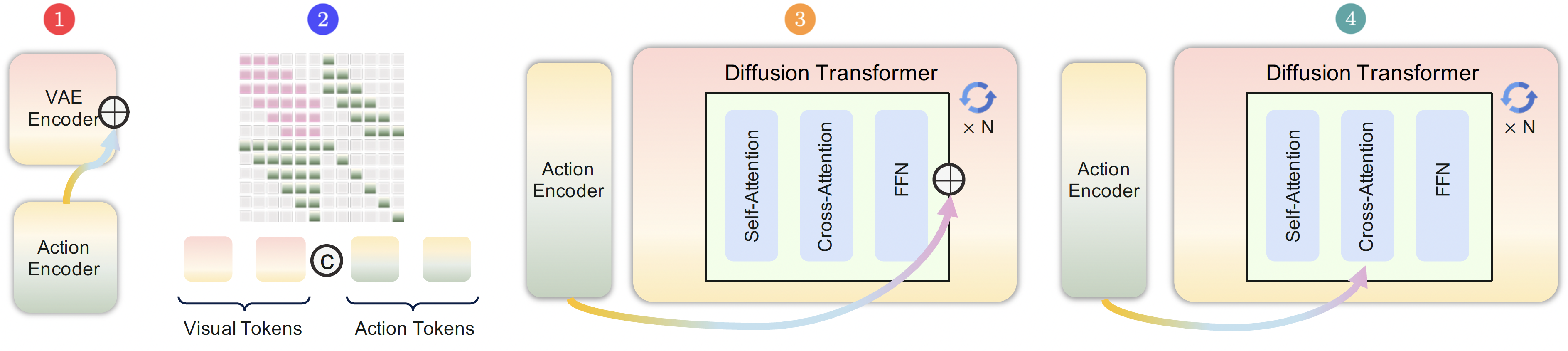
| Model | Name | Injection mode | Related line |
|---|---|---|---|
| Model 1 | External | Input-side latent modulation | Shallow action-conditioned baseline |
| Model 2 | Contextual | Action tokens merged into the main sequence | WHAM[33] |
| Model 3 | Residual | Injected through a side residual branch | ControlNet[34] |
| Model 4 | Internal | Action cross-attention inside each block | Matrix-Game 2.0[32] |
From the final results (details omitted here): among the four designs, Model 4 works best. In GUI environments with fine-grained timing and local interaction, injecting actions directly inside the block is the most effective way to teach the backbone how the interface should continue after an action. The data story is just as clear: 110 hours of supervised data beat roughly 1,400 hours of random data, and explicit visual supervision of the cursor works far better than pure coordinate supervision. The practical takeaway is straightforward: progress on GUI depends on stronger action semantics, clearer state transitions, and treating the cursor as a visual object to supervise.
Very few people initially expected video models to handle computer scenes this discrete, text-heavy, and action-sensitive. But once the task and data are organized well, they already produce interesting results on interface rendering, page transitions, short-term state continuation, local interaction, execution echo, and even some very early signs of working memory. Video models are still nowhere near the endpoint, but as an early prototype container they are already good enough to turn several otherwise abstract NC questions into concrete ones.
3.4 From prototype NC to CNC: what is still missing?
If we bring back the CNC condition table from Section 2, the overall conclusion of the current prototype is fairly clear: Turing complete has only been touched at the edge, universally programmable has barely appeared as an entry point, behavior-consistent holds only locally in controlled settings, and machine-native semantics is still clearer as a direction than as a result. NC is not about stacking agents, world models, and conventional computers on top of one another. It is about pulling some of the responsibilities now scattered across those objects back into the same learned runtime. What matters about the prototype is not that it is close to the endpoint, but that it makes several key constraints visible early.
4. If Neural Computer takes hold, software, hardware, and even “programs” will change
Put more plainly, Neural Computer is one view of what the next generation of computers may become. The most direct competition is likely to come from personalized super agents with strong memory, strong tool use, and persistent online presence. The table below places the three side by side.
Quick read: start with “what you actually get,” “how experience accumulates,” and “what gets installed.”
| ConventionalComputer | PersonalizedSuper Agent | CompletelyNeural Computer | |
|---|---|---|---|
| Basic positioning | |||
| What you actually get | A machine that precisely executes the programs you write | A persistent agent with strong memory and strong tool use that handles things on your behalf | A machine shaped by accumulated experience, with more capabilities staying inside the system |
| Organized around | Explicit programs | Task flow Persistent operation, but capability still comes from the external stack |
Runtime Persistent operation, with capabilities themselves inside the machine |
| How experience accumulates | You manually translate it into code, configuration, and rules | It gets written into memory, vector stores, workflows, skill files, MCPs, and prompts, then retrieved, injected, and orchestrated next time | It enters runtime directly and starts participating in later execution, instead of staying in an external retrieval layer |
| Installation and evolution | |||
| What gets installed | Software, libraries, scripts, and services | Tools, workflows, memory entries, skill descriptions | Capabilities themselves, along with installable, callable, composable sub-NNs |
| How it evolves | Through abstraction, interfaces, and program reuse; the machine itself changes little | Through foundation-model generalization and ongoing interaction; the system improves along the external stack | Through runtime updates and ongoing interaction; the machine changes along its internal capability structure |
| Substrate form | N/A | Closer to today's path: dense or MoE foundation models in the 1B-10T range | Closer to a next-generation substrate: a 10T-1000T machine that is sparser, more addressable, and more circuit-like |
| Position in the stack | |||
| Where it sits in the AI stack | Mainly the chips / infrastructure layer | Mainly spans the models and applications layers | Most directly changes the boundary between models and applications, and may push parts of infrastructure to reorganize around runtime |
| Current maturity | Fully mature Backed by 70+ years of engineering and still the substrate of most systems |
Already usable, and likely to keep improving quickly Systems like Claude, Cursor, and OpenClaw already show the early form |
The direction is plausible, and formal prototypes have appeared, but nothing close to a usable prototype yet The four conditions of Completely Neural Computer are still unmet |
If CNC really works, the first things to change would be what gets delivered and how the stack is organized. Today what gets installed is still software, tools, workflows, and memory entries. On the NC path, what gets installed would look more like capability itself. Code would still matter, but it would stop being the only doorway in. Instructions, demonstrations, interaction traces, and constraints would begin to do part of the installation work themselves. Even the word “program” would start to shift: it would no longer mean only a block of code, but a capability object that can be installed, composed, versioned, and updated over time.
From there the change would propagate into the stack and into the boundary of the machine itself. Software layout, hardware interfaces, update governance, and debugging would increasingly reorganize around the same continuously running machine. Phones, browsers, IDEs, and terminals would still remain, but they would feel more like different windows into that same machine. In the end, the change would reach not only the tool stack, but also the meaning of the word “computer.”
Note and acknowledgements: the content and views in this essay represent Mingchen Zhuge alone. Thanks to Wenyi Wang, Haozhe Liu, Shuming Liu, Yuandong Tian, Dylan R. Ashley, and Yutian Deng for thoughtful review comments. Some figures and materials are adapted from the original paper and related public sources.
References
If you want to cite this piece, you can use either the arXiv entry or the blog entry below.
arXiv BibTeX
@article{zhuge2026neural,
title={Neural computers},
author={Zhuge, Mingchen and Zhao, Changsheng and Liu, Haozhe and Zhou, Zijian and Liu, Shuming and Wang, Wenyi and Chang, Ernie and Lan, Gael Le and Fei, Junjie and Zhang, Wenxuan and others},
journal={arXiv preprint arXiv:2604.06425},
year={2026}
}
Blog BibTeX
@online{zhuge2026neuralcomputerblog,
author = {Mingchen Zhuge},
title = {Neural Computer: A New Machine Form Is Emerging},
year = {2026},
month = apr,
day = {7},
url = {https://metauto.ai/neuralcomputer/},
note = {Research essay},
urldate = {2026-04-09}
}
Reference List
- [1] Alex Graves, Greg Wayne, and Ivo Danihelka. Neural Turing Machines. arXiv:1410.5401, 2014.
- [2] Alex Graves et al. Hybrid computing using a neural network with dynamic external memory. Nature 538, 471-476 (2016).
- [3] MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. ICLR 2024.
- [4] OpenClaw. GitHub repository.
- [5] Mingchen Zhuge et al. AI with Recursive Self-Improvement. ICLR 2026 Workshop Proposals.
- [6] Schmidhuber, Jürgen. Making the world differentiable: on using self supervised fully recurrent neural networks for dynamic reinforcement learning and planning in non-stationary environments. Vol. 126. Inst. für Informatik, 1990.
- [7] David Ha and Jürgen Schmidhuber. World Models. 2018.
- [8] The Waymo World Model: A New Frontier For Autonomous Driving Simulation. Waymo Blog.
- [9] Demis Hassabis on Waymo World Model and Genie 3. X post.
- [10] NVIDIA Research. Cosmos World Foundation Models. NVIDIA, 2025.
- [11] World Labs. Marble: A Multimodal World Model. World Labs, 2025.
- [12] Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. GameNGen: Diffusion Models Are Real-Time Game Engines. Project page, 2024.
- [13] Google DeepMind. Genie 2: A large-scale foundation world model. DeepMind Blog, 2024.
- [14] Google DeepMind. Genie 3: A new frontier for world models. DeepMind Blog, 2025.
- [15] Ljubisa Bajic. The Path to Ubiquitous AI. Taalas.
- [16] Leo Gao, Achyuta Rajaram, Jacob Coxon, Soham V. Govande, Bowen Baker, and Dan Mossing. Weight-sparse transformers have interpretable circuits. arXiv:2511.13653, 2025.
- [17] Scott Reed and Nando de Freitas. Neural Programmer-Interpreters. arXiv:1511.06279, 2015.
- [18] David Ha, Andrew Dai, and Quoc V. Le. HyperNetworks. arXiv:1609.09106, 2016.
- [19] David Silver and Richard S. Sutton. Welcome to the Era of Experience. Preprint of a chapter to appear in Designing an Intelligence. 2025.
- [20] Sam Altman. The Gentle Singularity. Sam Altman Blog. Accessed March 15, 2026.
- [21] Dario Amodei. The Adolescence of Technology. Dario Amodei, January 2026.
- [22] Demis Hassabis, Dario Amodei, and Zanny Minton Beddoes. The Day After AGI. World Economic Forum Annual Meeting 2026 session, January 20, 2026.
- [23] Carver Mead. How we created neuromorphic engineering. Nature Electronics 3, 434-435 (2020).
- [24] Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. GPTSwarm: Language Agents as Optimizable Graphs. Proceedings of the 41st International Conference on Machine Learning, PMLR 235:62743-62767, 2024.
- [25] Mingchen Zhuge, Changsheng Zhao, Dylan R. Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, Yangyang Shi, Vikas Chandra, and Jürgen Schmidhuber. Agent-as-a-Judge: Evaluate Agents with Agents. Proceedings of the 42nd International Conference on Machine Learning, PMLR 267:80569-80611, 2025.
- [26] Wenyi Wang, Piotr Piękos, Li Nanbo, Firas Laakom, Yimeng Chen, Mateusz Ostaszewski, Mingchen Zhuge, and Jürgen Schmidhuber. Huxley-Gödel Machine: Human-Level Coding Agent Development by an Approximation of the Optimal Self-Improving Machine. arXiv:2510.21614, 2025.
- [27] ICLR 2026 Workshop: AI with Recursive Self-Improvement. Workshop website.
- [28] Peter H. Diamandis. Elon Musk: Optimus 3 Is Coming, Recursive Self-Improvement Is Already Here, and the Singularity #239. YouTube, March 11, 2026.
- [29] I. J. Good. Speculations Concerning the First Ultraintelligent Machine. Advances in Computers, Volume 6, 1966.
- [30] Jürgen Schmidhuber. Gödel Machines: Self-Referential Universal Problem Solvers Making Provably Optimal Self-Improvements. IDSIA Technical Report, revised December 27, 2004.
- [31] Wan Team. Wan: Open and Advanced Large-Scale Video Generative Models. arXiv:2503.20314, 2025.
- [32] Xianglong He et al. Matrix-Game 2.0: An Open-Source, Real-Time, and Streaming Interactive World Model. arXiv:2508.13009, 2025.
- [33] Anssi Kanervisto et al. World and Human Action Models towards gameplay ideation. Nature, 2025.
- [34] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding Conditional Control to Text-to-Image Diffusion Models. ICCV 2023.
- [35] Luke Rivard, Sun Sun, Hongyu Guo, Wenhu Chen, and Yuntian Deng. NeuralOS: Towards Simulating Operating Systems via Neural Generative Models. arXiv:2507.08800, 2025.